

What is Association Pattern Mining?

D
David is a seasoned cloud solutions architect/engineer with several years of experience architecting and building resilient, reliable and highly available systems in the cloud.
Search for a command to run...
David is a seasoned cloud solutions architect/engineer with several years of experience architecting and building resilient, reliable and highly available systems in the cloud.
No comments yet. Be the first to comment.
Application of scientific methods, processes, algorithms and systems to extract knowledge and insights from noisy data and its application to achieve a set objective/goal.
Guide a building a multi-agent AI system using Amazon Bedrock LLMAgent
Guide a building a multi-agent AI system using Amazon Bedrock LLMAgent

Implementing STRIDE on AWS

Automating Infrastructure Management

Unleashing the Power of AWS RDK and RDK-Lib: A Comprehensive Guide

Moto: Mock AWS Services - A library that allows you to easily mock out tests based on AWS infrastructure

When you go to a shopping mall, have you ever wondered why these pairs of items are placed next to each other; toothpaste and toothbrush, pens and writing pads, bread and jam, or apples and oranges? How about when shopping online? Have you ever thought of why you get recommendations based on what you just bought or added to a shopping cart, saying that Mr A who bought item A also bought item B? Do you think this is a mere coincidence? I DON'T THINK SO. Supermarkets keep sifting through the data they collect from their customers to find out the best ways to get the most money off their pockets.
The study of these relationships between different products in a retail store is known as Association Pattern Mining. In other words, association pattern mining is a mathematical approach to figuring out which products to stack close to each other especially for large stores so as to increase sales. As mentioned earlier, the application of association pattern mining has a huge impact on the strategy a retail store, for instance, will deploy in other to get more sales for their products. One very good example of this is the MEAL DEAL offered by some large retail stores like Tesco, Sainsbury, etc.
Wikipedia defines Association Rule Mining as a rule-based machine learning method for discovering interesting relations between variables in large databases. It is intended to identify strong rules discovered in databases using some measures of interestingness. In any given transaction with a variety of items, association rules are meant to discover the rules that determine how or why certain items are connected.
Let's get into the mathematics of this theory. The mathematical format for an association is denoted by the notation below:
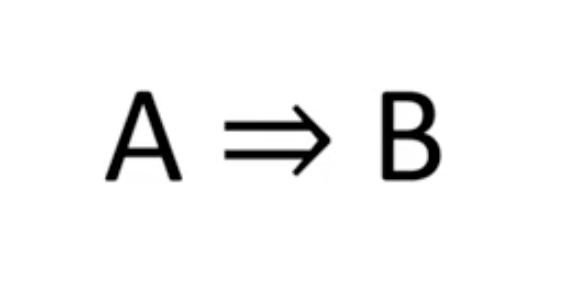 A is known as the antecedent(IF) while B is the consequent(THEN). This is just a mathematical way of saying if a customer buys A then there is a likelihood they will buy B consequently. The rules that guide our confidence level in making such rules can be measured in different ways. They include support, confidence, completeness, lift, and conviction. We will look at these briefly and also discuss the concept of RULE INTERESTINGNESS by Piatetsky Shapiro.
A is known as the antecedent(IF) while B is the consequent(THEN). This is just a mathematical way of saying if a customer buys A then there is a likelihood they will buy B consequently. The rules that guide our confidence level in making such rules can be measured in different ways. They include support, confidence, completeness, lift, and conviction. We will look at these briefly and also discuss the concept of RULE INTERESTINGNESS by Piatetsky Shapiro.
This measures how often a rule in a dataset happens. This is one of the most important metrics as several other rules are dependent on it.
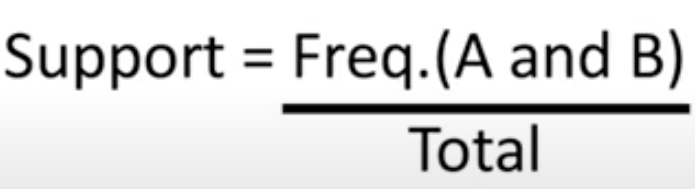
This answers the question, how often is our proposition true? This is also one of the most critical rules which other rules depend on.
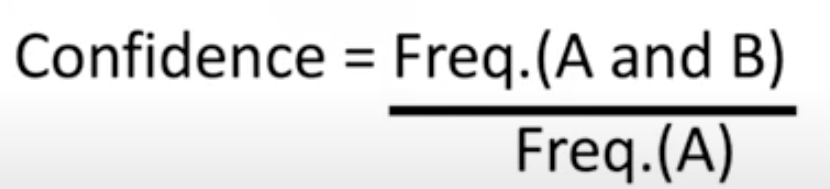
This measures how much of the "consequent" our rule captures, it can be seen as the right-half of the confidence measure.

This measures if things are dependent or independent of each other.

It measures how much of A occurs without B, in other words, it is the frequency of an incorrect prediction.
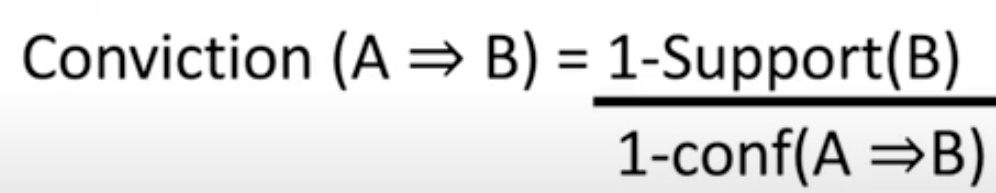
This is research by Piatetsky-Shapiro on how interesting a rule is. It is mathematically expressed as follows:

For further reading, explore these resources below:
We discussed the Association Pattern Mining. We also looked at the practical application and how it relates to our everyday activities. We also discussed the different rules and concepts around association pattern mining as well as their mathematical expressions. Our next discussion will be on a deeper dive into these concepts and code implementation in python. Do well to subscribe to my email list so you get updated when I post something new.